
NeRF at CVPR 2022
Published:
There are more than 50 papers related to Neural Radiance Fields (NeRFs) at the CVPR 2022 conference. With my former student and now colleague at Google Research, Andrew Marmon, we rounded up all papers we could find and organized them here for our edification, and your reading pleasure.
Below are all the papers at CVPR’22 that we could find by scanning titles and reading the associated papers, sometimes rather superficially because of the sheer number. Please forgive any mis-characterizations and/or omissions, and feel free to flag them by DM to @fdellaert on twitter.
Important note: all of the images below are reproduced from the cited papers, and the copyright belongs to the authors or the organization that published their papers, like IEEE. Below I reproduce a key figure or video for some papers under the fair use clause of copyright law.
NeRF
NeRF was introduced in the seminal Neural Radiance Fields paper by Mildenhall et al. at ECCV 2020. By now NeRF is a phenomenon, but for those that are unfamiliar with it, please refer to the original paper or my two previous blog posts on the subject:
In short, as shown in the figure below, a “vanilla” NeRF stores a volumetric scene representation as the weights of an MLP, trained on many images with known pose:
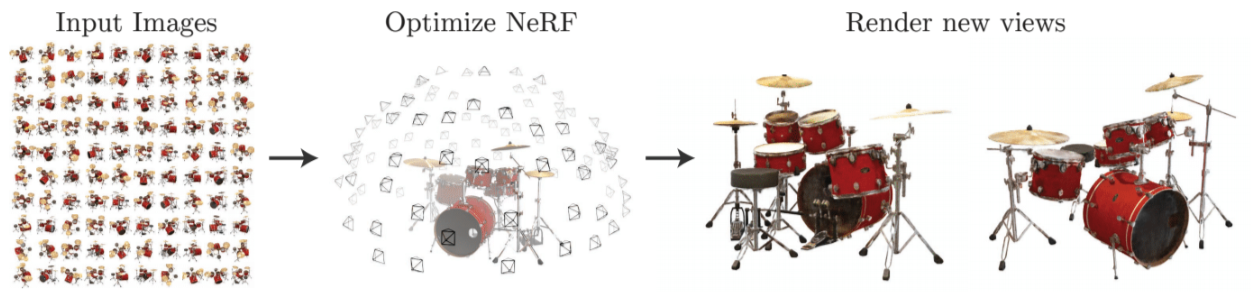 Figure: Nerf Overview.
Figure: Nerf Overview.
Fundamentals
Again, many papers address the fundamentals of view-synthesis with NeRF-like methods:
Teaser videos from NeRF in the Dark (see below) which is just one of many papers that blew us away in terms of image synthesis quality.
AR-NeRF replaces the pinhole-based ray tracing with aperture-based ray-tracing, enabling unsupervised learning of depth-of-field and defocus effects. (pdf)
Aug-NeRF uses three different techniques to augment the training data to yield a significant boost in view synthesis quality. (pdf)
Deblur-NeRF take an analysis-by-synthesis approach to recover a sharp NeRF from motion-blurred images, by simulating the blurring process using a learnable, spatially varying blur kernel. (pdf)
DIVeR use a voxel-based representation to guide a deterministic volume rendering scheme, allowing it to render thin structures and other subtleties missed by traditional NeRF rendering. (pdf) Best Paper Finalist
Ha-NeRF😆 uses an appearance latent vector from images with different lighting and effects to render novel views with similarly-styled appearance. (pdf)
HDR-NeRF learns a separate MLP-based tone mapping function to transform the radiance and density of a given ray to a high-dynamic range (HDR) pixel color at that point in the output image. (pdf)
Learning Neural Light Fields learn a 4D lightfield, but transform the 4D input to an embedding space first to enable generalization from sparse 4D training samples, which gives good view dependent results. (pdf)
Mip-NeRF-360 extends the ICCV Mip-NeRF work to unbounded scenes, and also adds a prior that reduces cloudiness and other artifacts. (pdf)
NeRF in the Dark modifes NeRF to train directly on raw images, and provide controls for HDR rendering including tone-mapping, focus, and exposure. (pdf)
NeRFReN enables dealing with reflections by splitting a scene into transmitted and reflected components, and modeling the two components with separate neural radiance fields. (pdf)
NeuRay improves rendering quality by predicting the visibility of 3D points to input views, enabling the radiance field construction to focus on visible image features. (pdf)
Ref-NeRF significantly improves the realism and accuracy of specular reflections by replacing NeRF’s parameterization of view-dependent outgoing radiance with a representation of reflected radiance. (pdf) Best Student Paper Honorable Mention
SRT “processes posed or unposed RGB images of a new area, infers a ‘set-latent scene representation’, and synthesizes novel views, all in a single feed-forward pass.” (pdf)
Priors
One important way to improve the synthesis of new views instead is with various forms of generic or depth-driven priors:
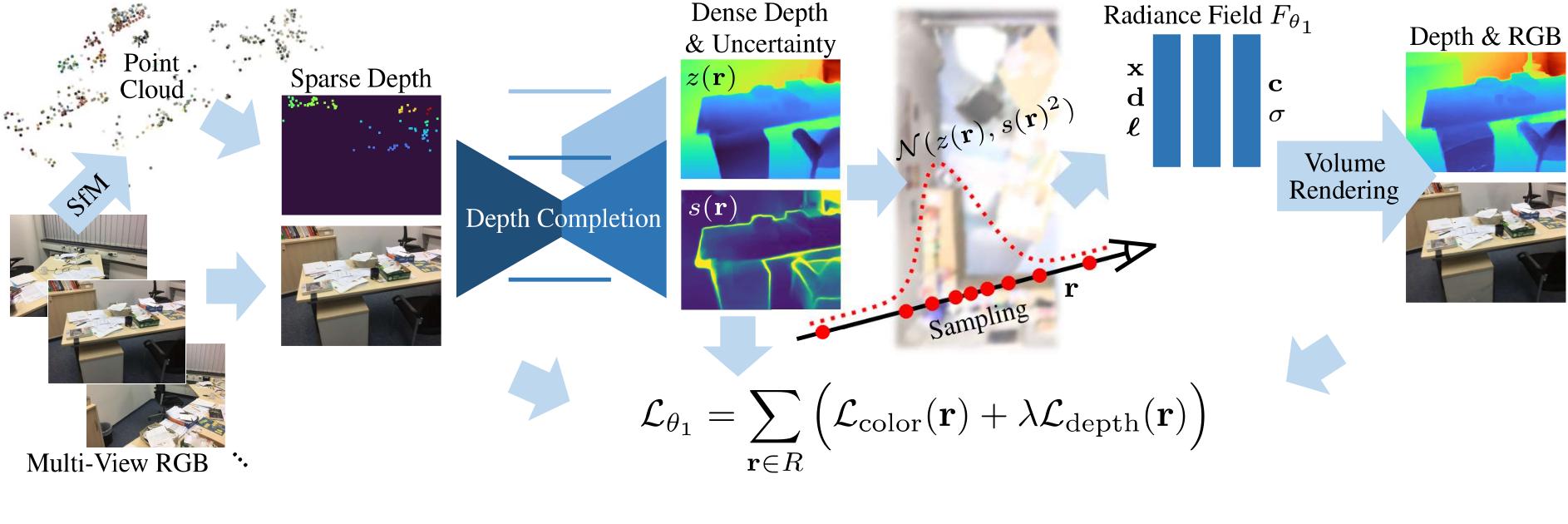 Figure: Dense Depth Priors for NeRF
Figure: Dense Depth Priors for NeRF
Dense Depth Priors for NeRF estimates depth using a depth completion network run on the SfM point cloud in order to constrain NeRF optimization, yielding higher image quality on scenes with sparse input images. (pdf)
Depth-supervised NeRF also uses a depth completion network on structure-from-motion point clouds to impose a depth-supervised loss for faster training time on fewer views of a given scene. (pdf)
InfoNeRF penalizes the NeRF overfitting ray densities on scenes with limited input views through ray entropy regularization, resulting in higher quality depth maps when rendering novel views. (pdf)
RapNeRF focuses on view-consistency to enable view extrapolation, using two new techniques: random ray casting and a ray atlas. (pdf)
RegNeRF enables good reconstructions from a view images by renders patches in unseen views and minimizing an appearance and depth smoothness prior there. (pdf)
Multi-View
Another approach is to use nearby reference views at inference time, following a trend set by IBRNet and MVSNet:
Result from from Light Field Neural Rendering (see below) which uses nearby views and a light-field parameterization to render very non-trivial effects.
GeoNeRF uses feature-pyramid networks and homography warping to construct cascaded cost volumes on input views that infer local geometry and appearance on novel views, using a transformer-based approach. (pdf)
Light Field Neural Rendering uses a lightfield parameterization for target pixel and its epipolar segments in nearby reference views, to produce high-quality renderings using a novel transformer architecture. (pdf) Best Paper Finalist
NAN builds upon IBRNet and NeRF to implement burst-denoising, now the standard way of coping with low-light imaging conditions. (pdf)
NeRFusion first reconstructs local feature volumes for each view, using neighboring views, and then uses recurrent processing to construct a global neural volume. (pdf)
Performance
A big new trend is the emergence of voxel-based, very fast NeRF variants, many foregoing the large MLP at the center of the original NeRF paper:
Plenoxels (see below) is one of the no-MLP papers that took the NeRF community by storm. DVGO (also below) and instant NGP method, published not at CVPR but at SIGGRAPH 22, are other papers in this space. Goodbye long training times?
DVGO replaces the large MLP with a voxel grid, directly storing opacity as well as local color features, interpolated and then fed into a small MLP to produce view-dependent color. (pdf)
EfficientNeRF learns estimated object geometry from image features for efficient sampling around the surface of the object, reducing the time it takes to render and improving radiance field construction. (pdf)
Fourier PlenOctrees tackles “efficient neural modeling and real-time rendering of dynamic scenes” using “Fourier PlenOctrees”, achieving a 3000x speedup over NeRF. (pdf)
Plenoxels foregoes MLPs altogether and optimizes opacity and view-dependent color (using spherical harmonics) directly on a 3D voxel grid. (pdf)
Point-NeRF uses MVS techniques to obtain a dense point cloud, which is then used for per-point features, which are then fed to a (small) MLP for volume rendering. (pdf)
Large-scale
Large-scale scenes are also of intense interest, with various efforts in that dimension:
Block-NeRF (see below) shows view synthesis derived from 2.8 million images.
Block-NeRF scales NeRF to render city-scale scenes, decomposing the scene into individually trained NeRFs that are then combined to render the entire scene. Results are shown for 2.8M images. (pdf)
Mega-NeRF decomposes a large scene into cells each with a separate NeRF, allowing for reconstructions of large scenes in significantly less time than previous approaches. (pdf)
Urban Radiance Fields allows for accurate 3D reconstruction of urban settings using panoramas and lidar information by compensating for photometric effects and supervising model training with lidar-based depth. (pdf)
Articulated
A second emerging trend is the application of neural radiance field for articulated models of people, or cats 😊:

BANMo (see below) creates a deformable NeRF from your cat videos!
BANMo combines deformable shape models, canonical embeddings, and NeRF-style volume rendering to train high-fidelity, articulated 3D models from many casual RGB videos. (pdf)
DoubleField trains a surface field as well as radiance field, using a shared feature embedding, to allow for high-fidelity human reconstruction and rendering on limited input views. (pdf)
HumanNeRF optimizes for a volumetric representation of a person in a canonical pose, and estimates a motion field for every frame with non-rigid and skeletal components. (pdf)
HumanNeRF (2) estimates human geometry and appearance through a dynamic NeRF approach along with a neural appearance blending model from adjacent views to create dynamic free-viewpoint video using as few as six input views. (pdf)
NeuralHOFusion learns separate human and object models from a sparse number of input masks extracted from RGBD images, resulting in realistic free-viewpoint videos despite occlusions and challenging poses. (pdf)
Structured Local Radiance Fields uses pose estimation to build a set of local radiance fields specific to nodes on an SMPL model which, when combined with an appearance embedding, yields realistic 3D animations. (pdf)
Surface-Aligned NeRF maps a query coordinate to its dispersed projection point on a pre-defined human mesh, using the mesh itself and the view direction to be input to the NeRF for high-quality dynamic rendering. (pdf)
VEOs use a multi-view variant of non-rigid NeRF for object reconstruction and tracking of plushy objects, which can then be rendered in new deformed states. (pdf)
Portrait
Some papers are focused on the generation of controllable face images and/or 3D head models for people, and cats:
GRAM (see below) focuses its radiance fields to be sampled near the surface for some amazing results.
EG3D is a geometry-aware GAN that uses a novel tri-plane volumetric representation (somewhere between implicit and voxels) to allow for real-time rendering to a low-res image, upscaled via super-resolution. (pdf)
FENeRF learns a 3D-aware human face representation with two latent codes, which can generate editable and view-consistent 2D face images. (pdf)
GRAM uses a separate manifold predictor network to constrain the volume rendering samples near the surface, yielding high-quality results with fine details. (pdf)
HeadNeRF integrates 2D rendering into the NeRF rendering process for rendering controllable avatars at 40 fps. (pdf)
RigNeRF enables full control of head pose and facial expressions learned from a single portrait video by using a deformation field that is guided by a 3D morphable face model. (pdf)
StyleSDF combines a conditional SDFNet, a Nerf-style volume renderer, and a 2D style-transfer network to generate high quality face models/images. (pdf)
Editable
Controllable or editable NerFs are closely related:

With CLIP-NeRF (see below) you can edit NeRFs with textual guidance, or example images.
CLIP-NeRF supports editing a conditional model using text or image guidance via their CLIP embeddings. (pdf)
CoNeRF takes a single video, along with some attribute annotations, and allow re-rendering while controlling the attributes independently, along with viewpoint. (pdf)
NeRF-Editing allows for editing of a reconstructed mesh output from NeRF by creating a continuous deformation field around edited components to bend the direction of the rays according to its updated geometry. (pdf)
Conditional
Continuing a trend started at ICCV is conditioning NeRF-like models on various latent codes:
🤣LOLNeRF uses pose estimation and segmentation techniques to train a conditional NeRF on single views, which then at inference time can generate different faces with the same pose, or one face in different poses. (pdf)
Pix2NeRF extends π-GAN with an encoder, trained jointly with the GAN, to allow mapping images back to a latent manifold, allowing for object-centric novel view synthesis using a single input image. (pdf)
StylizedNeRF “pre-train a standard NeRF of the 3D scene to be stylized and replace its color prediction module with a style network to obtain a stylized NeRF.” (pdf)
Composition
Close to my interests, compositional approaches that use object-like priors:
Panoptic Neural Fields (PNF) (see below) has many object-NeRFs and a “stuff”-NeRF, supporting many different synthesis outputs.
AutoRF learns appearance and shape priors for a given class of objects to enable single-shot reconstruction for novel view synthesis. (pdf)
PNF fits a separate NeRF to individual object instances, creating a panoptic-radiance field that can render dynamic scenes by composing multiple instance-NeRFs and a single “stuff”-NeRF. (pdf)
Other
Finally, several different (and pretty cool!) applications of NeRF:

DyNeRF (see below) allows free-viewpoint re-rendering of a video once latent descriptions for all frames have been learned.
Dream Fields synthesizes a NeRF from a text caption alone, minimizing a CLIP-based loss as well as regularizing transmittance to reduce artifacts. (pdf)
DyNeRF uses compact latent codes to represent the frames in a 3D video and is able to render the scene from free viewpoints, with impressive volumetric rendering effects. (pdf)
Kubric is not really a NeRF paper but provides “an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes” that can directly provide training data to NeRF pipelines. (pdf)
NICE_SLAM uses a hierarchical voxel-grid NeRF variant to render RGBD, for a real-time and scalable parallel tracking and mapping dense SLAM system for RGBD inputs. (pdf)
STEM-NeRF use a differentiable image formation model for Scanning Transmission Electron Microscopes (STEMs) (pdf)
Concluding Thoughts
I am happy that with Panoptic Neural Fields I am finally myself a co-author on a NerF paper, but this is probably the last of these blog posts I will write: it is getting too hard to keep track of all the papers in this space, and growth seems exponential. It is increasingly hard, as well, to come up with ideas in this space without being scooped: I myself was scooped after some months of work on an idea, and I know of many others that found themselves in the same boat. Nevertheless, it is an exciting time to be in 3D computer vision, and I am excited to see what the future will bring.